
Compose a service landscape to ingest, store and process huge amounts of unstructured data.
What is a data lake and why we should care?
The definition of a data lake has changed over time but Wikipedia offers a good summary:
“[..]A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files. A data lake is usually a single store of data including raw copies of source system data, sensor data, social data etc., and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning. [..]”
“Data lake”
~~ Wikipedia, Wikimedia Foundation, 17:55, 13 Sept 2023 , https://en.wikipedia.org/wiki/Datalake.
With a data lake we can explore and discover huge amounts of data. Usually in an attempt to get valuable business insights like customer preference, market trends or patterns. Data could also be sold to other companies.
Unlike other storage approaches, there is no need to define use cases or schemas upfront. The data lake offers the flexibility to store everything now and define/analyze later.
Done right, there are no hard scaling limits and self-service for analysts speeds up the process.
What do we want to achieve?
We want to compose a service landscape, which allows us to ingest and store huge amounts of unstructured data, to be processed and analysed on a large scale. We utilize managed services and pay-as-you-go billing where possible.
How to get started?
To get started, we need to cover these four areas:
| Storage | Ingestion | Processing | Analysis |
|---|---|---|---|
| Where to put all the data? | How to get data loaded into the lake? | How to extract, transform and load huge amounts of data (ETL)? | How to get insights from your data? |
| How can we catalog it and keep track of everything? | Real-time and batch. | Change data formats, generate and update meta information. | Analyse our data with graphical tools or with interactive developer notebooks. |
Storage
We need a storage engine that:
- can be easily scaled up to our storage needs
- has high availability and durability
- needs little to no maintenance from us
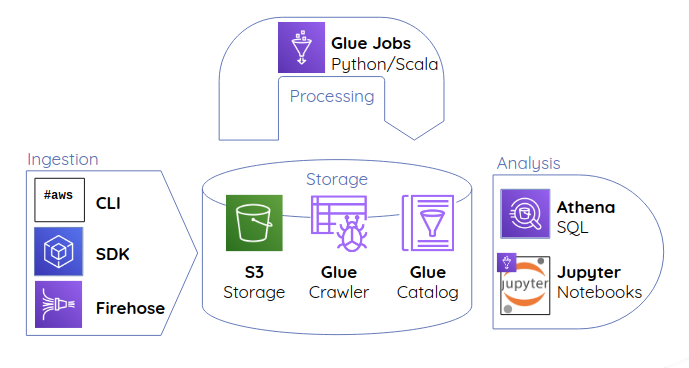
Amazon Simple Storage Service (S3) is our choice here:
- key-value storage which integrates with a lot of other services
- theoretically no storage limit
- designed for a durability of 99,999999999% and standard availability of 99,99%
- fully managed by AWS and pay-as-you-go pricing model
Data catalog
Storing isn’t enough. We also need to catalog our data and store meta information like data formats and schemata.
AWS Glue can be used as a centralized register. It can crawl our data to discover meta information and store it in tables.
Ingestion
Since our storage is S3, we have a lot of options to get data loaded.
We start with three methods:
- AWS CLI - move data from the command line
- AWS SDK - manipulate data on S3 in 9 different programming languages
- Kinesis Data Firehose - managed service lets us aggregate and write real time data to S3.
Processing
Our data is stored in S3 and cataloged by Glue. Now we can start to work with it. To process large amounts of data, we need something that can handle huge amounts of data, without the need to maintain a complex compute cluster (at least by us).
This can be achieved with Glue Jobs. Jobs are Spark scripts written in Python or Scala and executed in a fully managed compute cluster.
Analysis
We can use AWS Athena to query huge amounts of data with standard SQL. Athena integrates seamlessly with our data catalog, is fully managed, lighting fast and offers pay-as-you-go pricing.
For everything else we can use managed Jupyter notebooks. AWS Sagemaker lets us spin up on demand notebooks with Spark endpoints to access our data catalog and analyze our data with Python.
The full picture
What to consider next
This is only a starting point to get first experience in a fully managed high performance environment.
Once you get familiar with the services, I highly recommend diving deeper into Access Management (IAM), Encryption and Metrics before you put critical data in your lake.

